AIの『頭脳』を自前で設計し始めた日 — OpenAIが初の専用チップ『Jalapeño』をたった9か月で形にしたわけ
【国際・海外企業】連載・AI・イノベ【経済・半導体電子部品】【科学・半導体】米国
目次
AIの『頭脳』を自前で設計し始めた日 — OpenAIが初の専用チップ『Jalapeño』をたった9か月で形にしたわけ
概要
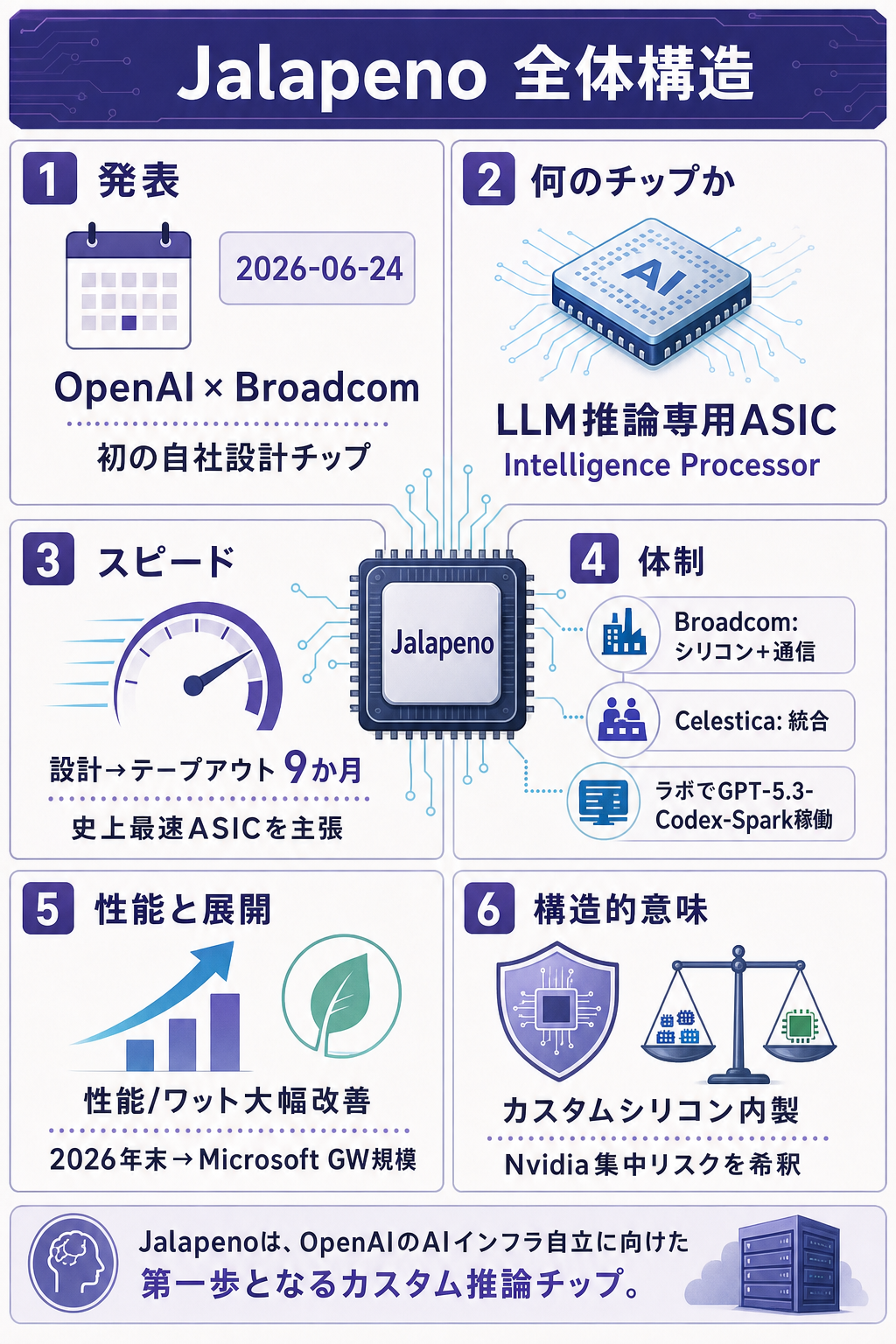
「世界一使われている AI が、その AI を動かすための半導体を、ついに自分で設計しはじめた」——そんな転換点が、2026 年 6 月 24 日に訪れました。OpenAI が半導体大手 Broadcom(ブロードコム) と組み、自社初の専用チップ『Jalapeño(ハラペーニョ)』 を共同発表したのです。
これは ChatGPT のような大規模言語モデル(LLM)を「動かす(=推論する)」ことだけに特化して、ゼロから設計された半導体です。
- 何がスゴいのか — 設計開始から製造直前の最終工程(テープアウト)まで わずか9か月。OpenAI と Broadcom は「高性能半導体として史上最速の ASIC 開発サイクル」だと表現しています
- 狙い — 汎用の AI 計算ではなく 「LLM の推論」だけに用途を絞り込む ことで、電力あたりの性能(性能/ワット)を「現行最先端より大幅に良くする」と公表
- 体制 — チップ本体の実装と通信技術は Broadcom、基板・ラック・システム統合は Celestica(セレスティカ) が担当。2026 年末から実際の稼働を開始し、Microsoft などのデータセンターでギガワット(GW)規模へ広げる計画
「AI 企業が、AI を動かす半導体まで自前で持つ時代"」——本稿では、この『Jalapeño』というニュースを、専用チップとは何か・なぜ自前で作るのか・FP&A から見た投資判断の勘所の3層で、専門外の方にもわかるよう順番に解きほぐします。
詳細 — 何が「6月24日」に発表されたのか
そもそも「推論専用チップ」とは何か
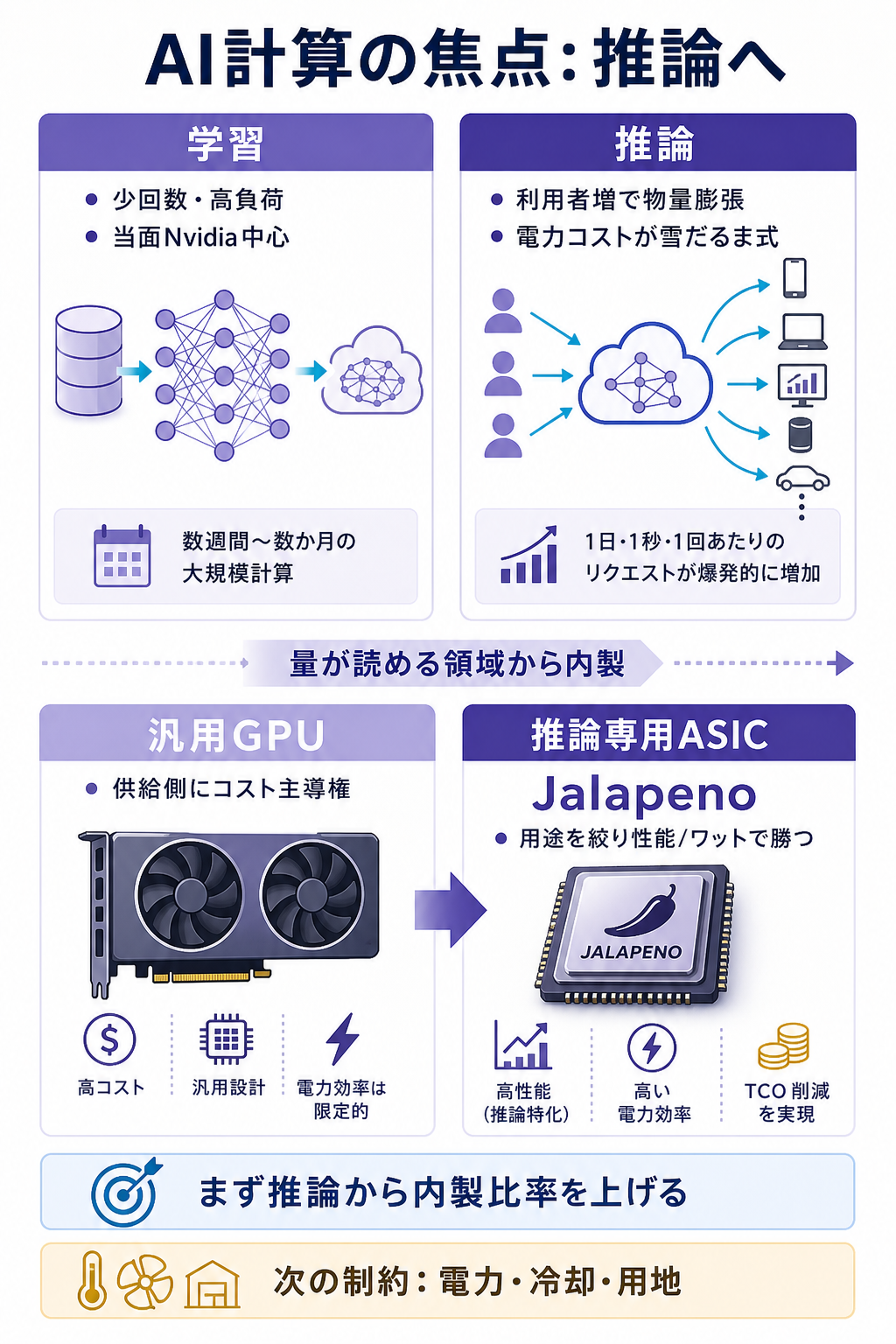
AI の計算には、大きく2つの局面があります。
1つは AI に大量のデータを学習させる 「学習(トレーニング)」、もう1つは学習済みの AI に質問を投げて答えを出させる 「推論(インファレンス)」 です。
私たちが ChatGPT に話しかけるたびに走っているのは後者の「推論」で、利用者が増えるほど 推論の回数(とその電気代)が雪だるま式に膨らむ という構造になっています。
補足: 用語のミニ解説
- LLM(大規模言語モデル) — ChatGPT のような、大量の文章を学習した AI の中身。
- 推論(インファレンス) — 学習済み AI に入力を与えて出力を得る処理。サービス運用中はこちらが延々と回り続ける。
- ASIC(特定用途向け集積回路) — 「ある用途だけ」に最適化して作る専用チップ。汎用品より設計の自由度は低い代わりに、用途が合えば電力効率・コスト効率で勝ちやすい。
- テープアウト — チップの設計データを工場へ渡す「製造直前の確定工程」。ここに至るまでが半導体開発の最難関。
『Jalapeño』は、この「推論」だけに用途を絞った ASIC です。
OpenAI はこれを 「Intelligence Processor(インテリジェンス・プロセッサ)」 と名付け、「LLM 推論で本当に効く部分——計算カーネル、メモリの動かし方、ネットワーク、配信パターン——に合わせて設計を最適化した」と説明しています。
「9か月」という異例のスピード
今回いちばん驚かれているのは、開発期間の短さです。通常、最先端半導体は設計からテープアウトまで数年かかることも珍しくありません。それを 9か月 で到達したと両社は主張しています。
補足: なぜ9か月で到達できたのか(公表内容ベース)
- ソフトとハードの一体開発 — OpenAI のモデル側エンジニアと Broadcom のシリコン実装チームが密に協働。「どんな計算が一番効くか」を知る側が直接設計に関与した。
- AI で AI チップを作る — OpenAI は 自社の AI モデルを設計・最適化の一部に活用 したと公表。「AI が次世代 AI の開発を速める」という、いま注目される現象の実例。
- 通信技術の流用 — Broadcom の Tomahawk ネットワーキング技術を組み合わせ、チップ間をつなぐ部分を内製の蓄積で素早く固めた。
ラボでは、エンジニアリングサンプル(試作段階のチップ)が 量産時の目標周波数・電力で実際の機械学習処理を稼働させており、OpenAI のコーディング向けモデル「GPT-5.3-Codex-Spark」が動いていると明かされています。
「動く目処が立っている」という段階まで来ている、ということです。
性能の主張は「性能/ワット」で語られている
公式発表が強調するのは、生の速さではなく 「性能/ワット(電力あたりの性能)が現行最先端より大幅に良い」 という点です。
これは、データセンターのコストと電力制約がボトルネックになっている今の AI 業界にとって、最も刺さる指標です。
あわせて「実効利用率を理論ピーク性能にかなり近づける」とも述べています。
補足: 公式の主張と、二次報道の数値を切り分ける
- 公式が言っていること — 「性能/ワットが大幅改善」「実効利用率が理論ピークに近い」。具体的な対 Nvidia 比較の数値は公式発表には記載がない。
- 二次報道が伝えていること — 一部メディアは「推論コストが現行 GPU 比で約半分」「OpenAI は 2025 年に ChatGPT 提供で約 140 億ドルを費やした」等と報じているが、これらは公式の数字ではないため、本稿では参考情報として扱う。
展開計画は、2026 年末に初期展開を開始し、複数世代にわたるロードマップで拡大。
Microsoft をはじめとするデータセンター・パートナーと ギガワット規模 で広げるとしています。
Broadcom の Hock Tan CEO は「これは複数世代ロードマップの始まりにすぎない」と述べました。
発表当日、株式市場では Broadcom 株が上昇する一方、Nvidia 株はほぼ横ばい〜小幅安と報じられました(株価反応は二次情報)。
もし深堀するなら
ここから先は、この発表を「OpenAI のニュース」で終わらせず、業界構造や投資判断につなげるための「もう一段の問い」です。
- なぜ AI 企業が自前チップに動くのか(垂直統合の論理) — AI サービスの原価は、突き詰めると「半導体の電力効率」で決まります。汎用 GPU を外から買い続ける限り、コストの主導権はチップ供給側にある。用途を絞った自社設計に踏み込むのは、Google(TPU)・Amazon(Trainium/Inferentia)・Meta(MTIA)が先行してきた道で、OpenAI もそこへ合流したと読めます。
- 「脱 Nvidia」ではなく「Nvidia 依存の希釈」 — 重要なのは、これが Nvidia の即時代替ではないこと。最先端の「学習」では当面 Nvidia が中心であり、Jalapeño は まず「推論」という最も物量が出る領域から内製比率を上げる 設計です。供給先を一社に握られるリスク(集中リスク)を下げる動きと捉えるのが妥当です。
- 設計を担う Broadcom が「もう一人の勝者」 — 自社チップを持ちたい巨大テック各社の設計を一手に引き受けているのが Broadcom です。Google・Meta・OpenAI・Apple などの カスタムシリコンの「裏方」 として、AI ブームのもう一つの受益者になりつつあります。「派手な完成品」ではなく「それを作る装置・部品・設計」に投資妙味が移る、という視点。
- 電力とデータセンターが次の制約 — ギガワット規模という言葉が示す通り、ボトルネックはもはやチップ単体ではなく 電力・冷却・用地 に移りつつあります。チップの性能/ワット改善は、この物理制約を緩める手段でもある。次は「電力・送配電・データセンター不動産」が論点になります。
🔎 FP&A実務的なアプローチの考察(クリックで展開/全員必読ではありません)
ここからは、企業の経営企画・FP&A 部門の視点で、この「自社設計チップ」のニュースをどう自社の投資判断や原価管理に引きつけて読むかの深掘りです。
「作るか・買うか(Make or Buy)」を単価でなく総保有コストで判断する — Jalapeño の本質は、巨額の先行開発投資(設計・人材・テープアウト)を引き受けてでも、運用フェーズの単位コスト(推論1回あたりの電力・原価)を下げにいく という意思決定です。
FP&A の現場でも、内製化やシステム自社開発の是非は「初期投資 vs 外部調達単価」だけでなく、TCO(総保有コスト)=初期投資+運用年数×年間運用コスト で比較すべきです。
「単価が安い外部調達」が、量が膨らむと総額で割高になる——という逆転は、まさに OpenAI の推論コストで起きていることです。
損益分岐となる『量』を先に置く — 内製化の投資判断では、「年間どれだけの量が出れば、先行投資を運用コスト削減で回収できるか」という 損益分岐ボリューム を最初に置くのが定石です。
Jalapeño も「推論という最も量が出る領域」から始めているのは、回収の効く量が見込める領域だからと読めます。
自社の RPA・内製システム・専用設備の投資稟議でも、「何年で・どの稼働率なら回収できるか」を感応度分析(量が±20% ブレたら回収年数はどう動くか)で示すと、意思決定の質が上がります。
一過性の改善と構造的な改善を分けて評価する — チップの「性能/ワット改善」は構造的(=毎年効く)コスト改善です。
一方、後述するマコーミックの『関税還付』のような一過性の改善とは性質が違います。
FP&A は、利益率の改善要因を必ず 「来年も続くもの/今年だけのもの」 に仕分けて経営に報告すべきです。
構造改善(=設備・プロセス由来)は来期予算に織り込めますが、一過性は織り込んではいけません。
試算例(投資回収のイメージ) — 仮に、ある処理を外部クラウドに払うと年間 100 億円、専用設備を 150 億円で内製すると年間運用が 40 億円で済むとします。
内製による年間削減額は 100−40=60 億円。
初期投資 150 億円は 150÷60=2.5 年 で回収でき、以降は毎年 60 億円が浮く計算です。
ただし量が想定の 7 割に減ると削減額も目減りし回収は延びる——だからこそ「量の確実性」が内製判断の生命線になります。
この「規模が読める領域から内製する」という順番こそ、Jalapeño が推論から入った合理性そのものです。
まとめ
- OpenAI は 2026 年 6 月 24 日、Broadcom と共同で 自社初の推論専用チップ『Jalapeño』 を発表
- 設計からテープアウトまで わずか9か月(「史上最速の ASIC 開発サイクル」と主張)、Broadcom がシリコン実装と通信、Celestica が統合を担当
- 用途を LLM 推論に特化し、性能/ワットを現行最先端より大幅改善すると公表(対 Nvidia の具体数値は公式未記載)
- ラボでは GPT-5.3-Codex-Spark が稼働、2026 年末から初期展開し Microsoft 等とギガワット規模へ拡大
- 構造的には Google・Amazon・Meta が先行した カスタムシリコン内製 への合流であり、即時の「脱 Nvidia」ではなく「集中リスクの希釈」
- FP&A 視点では、「Make or Buy は単価でなく TCO で」「損益分岐ボリュームを先に置く」「構造改善と一過性改善を仕分ける」が実務に落とせる教訓
理解度チェック
Q1. 『Jalapeño』が用途を絞って最適化した処理は、次のうちどれですか?
- A. AI に大量データを学ばせる「学習(トレーニング)」
- B. 学習済み AI に入力を与えて答えを出す「推論(インファレンス)」
- C. 半導体の製造(前工程)
- D. データセンターの冷却制御
解答
B. 推論(インファレンス)。
Jalapeño は LLM の「推論」に特化した ASIC(特定用途向けチップ)として設計された。
サービス運用中は推論が延々と回り続け、利用者増に比例してコストが膨らむため、ここを効率化する経済合理性が大きい。
Q2. OpenAI と Broadcom が公式発表で性能の主張に使った主な指標はどれですか?
- A. Nvidia 比で推論コストが約50%安い
- B. 演算の最高クロック周波数
- C. 性能/ワット(電力あたりの性能)が現行最先端より大幅に良い
- D. 1チップあたりの製造単価
解答
C. 性能/ワット。
公式は「性能/ワットが現行最先端より大幅に良い」「実効利用率が理論ピークに近い」と述べている。
「対 Nvidia でコスト約半分」は二次報道由来で公式には記載がなく、事実として断定はできない。
Q3. FP&A の「Make or Buy(作るか・買うか)」判断で最も適切な考え方はどれですか?
- A. 外部調達の単価が内製の単価より安ければ必ず買う
- B. 初期投資額だけを見て、小さいほうを選ぶ
- C. 初期投資+運用年数×年間運用コスト(TCO)で比較し、損益分岐となる量を先に置く
- D. 競合が内製しているなら自社も必ず内製する
解答
C. TCO で比較し、損益分岐ボリュームを先に置く。
単価が安い外部調達でも、量が膨らむと総額で割高になる逆転が起こりうる。
内製の先行投資が「何年で・どの稼働率なら回収できるか」を感応度分析で示すのが定石。
Jalapeño が「量が読める推論」から入ったのも同じ論理。
関連リンク
- 出典・一次情報
- 業界レポート(社内ナレッジ連動)
- 関連の既出記事
出典・factcheck
- primary_source_url: OpenAI 公式発表ページ「OpenAI and Broadcom unveil LLM-optimized inference chip」(Jalapeño)
- secondary_source_url: Broadcom 投資家向けリリース / TechCrunch・CNBC(発表日・株価反応)
- source_confidence: High(OpenAI 公式ページを Jina 経由で取得し、チップの位置づけ・9か月テープアウト・Broadcom/Celestica の役割・GPT-5.3-Codex-Spark のラボ稼働・2026年末からの展開・Microsoft とのギガワット計画・Hock Tan 発言を確認)
- verification_note: 発表日 2026-06-24 は TechCrunch/CNBC/Broadcom で一致。『Nvidia 比で推論コスト約50%減』『2025 年の ChatGPT 提供コスト約140億ドル』『TSMC が製造』等は二次報道由来で公式未記載のため、本文では事実として断定せず「二次報道」と明示して扱った。株価反応(Broadcom 上昇/Nvidia ほぼ横ばい)も二次情報。