NVIDIA Nemotron 3 Ultra 550B+DGX Station — 『ローカルLLMはどこまで動くか』を Mac Studio と比較して検証する
【国際・海外企業】連載・AI・イノベ米国【科学・AI】【科学・半導体】
#AI・イノベ#ローカルLLM#NVIDIA#AppleSilicon
目次
- 概要
- 詳細
- 発表されたもの(GTC Taipei 6/1)
- ローカルLLMは「どこまで」「どれだけ簡単に」動くか(2026年の実機事情)
- ポイント — FP&Aの勘所
- Mac Studio vs DGX Station — 10倍の価格差をどう読むか
- Nemotron 3 Ultra 550B は「Macで動く」— これが最大の含意
- もし深堀するなら
- 観点:自分のFP&Aへの示唆
- 関連リンク
- 📱 X投稿文案(昇格成果物)
- 案A:主要切り口(数値インパクト)
- 案B:別切り口(Macとの比較=現実解)
- 案C:FP&A角度(損益分岐)
- 🖼️ 画像生成 handoff seed(C3契約)
NVIDIA Nemotron 3 Ultra 550B+DGX Station — 『ローカルLLMはどこまで動くか』を Mac Studio と比較して検証する
- primary_source: NVIDIA GTC Taipei 基調講演(2026-06-01)/NVIDIA Newsroom(DGX Station for Windows 製品ページ)。一次原本 URL は要再特定
- primary_source_url: URL未取得(要再特定。NVIDIA 公式 newsroom の GTC Taipei keynote ページ)
- primary_source_checked_at: 未確認(一次keynote)/2026-06-12(スペック・Mac比較は二次照合)
- secondary_source: wccftech「DGX Station Upgraded With GB300...748GB Memory, 20 PFLOPs」→ https://wccftech.com/nvidia-dgx-station-upgraded-gb300-blackwell-ultra-desktop-superchip/ /Tom's Hardware/ServeTheHome/TechRadar(MSI WS300 $85,000)/TechRadar・MacRumors「M3 Ultra runs DeepSeek R1 671B」/SitePoint・MindStudio「Local LLMs 2026」
- source_confidence: Medium(Nemotron のベンチは NVIDIA 主張、ハード・Mac 比較は二次複数照合済)
何が起きたか: NVIDIA が GTC Taipei(6/1)で、商用可・自社ホスト可能な open weights モデル Nemotron 3 Ultra(550B) と、デスクサイドAIスパコン DGX Station(GB300・748GB・20 PFLOPS FP4)を発表。
「API課金からオンプレ推論へ」の閾値を下げた。
市場/業界の反応: フロンティア級の open weights を NVIDIA 自社が投入=モデルのコモディティ化が加速。
差別化軸が「モデル性能」から「ツール・MCPエコシステム・ガバナンス」へ移る。
投資/FP&A への意味: 自社ホストAIの損益分岐(API opex → capex+電力)を試算する好機。
だが「ローカルLLMはどこまで動くか」を冷静に見ると、$100K超のDGX Stationより、$9,500のMac Studio 512GBの方が現実解になる場面が多い。
概要
NVIDIA は2026年6月1日、台北の GTC Taipei 基調講演で、開放型・自社ホスト可能な大型LLM「Nemotron 3 Ultra」(550Bパラメータ、permissive 商用ライセンス、open weights)と、デスクサイドAIスーパーコンピューター「DGX Station(GB300)」を発表した。
Nemotron 3 Ultra は agentic ベンチ「PinchBench Agent Productivity」で 91%(NVIDIA 主張)、従来比 5×推論加速・30%コスト削減を謳う。
DGX Station は 748GB coherent memory・**20 PFLOPS(FP4)**でデスクサイドの trillion-parameter 推論を可能にする。
KK の追加リサーチ要望は「ローカルLLMがどこまで動かしやすく、Macとの比較」。
この記事は発表内容に加え、ローカルLLMの実機事情(Ollama/LM Studio/MLX)と、DGX Station vs Mac Studio の損得を統合する。
詳細
発表されたもの(GTC Taipei 6/1)
- Nemotron 3 Ultra: 550Bパラメータ、permissive 商用ライセンス、open weights。PinchBench 91%(二次のみ)、推論5×・コスト30%減(NVIDIA 主張)。長時間実行エージェント(multi-step・複数ツール呼び出し)向け最適化
- DGX Station(GB300): GB300 Grace Blackwell Ultra Desktop Superchip。748GB coherent memory(496GB LPDDR5X @396GB/s + 252GB HBM3e @7.1TB/s)、20 PFLOPS FP4、72 Neoverse V2 コア、NVLink-C2C 900GB/s。価格は約 $100K-125K(MSI XpertStation WS300 は $85,000)。Asus/Dell/HP/Gigabyte/MSI/Supermicro 経由で出荷中。「DGX Station for Windows」版も提供
- 並行発表: ServiceNow 提携拡張、Adobe・SAP・Salesforce など17社が NVIDIA Agent プラットフォーム採用
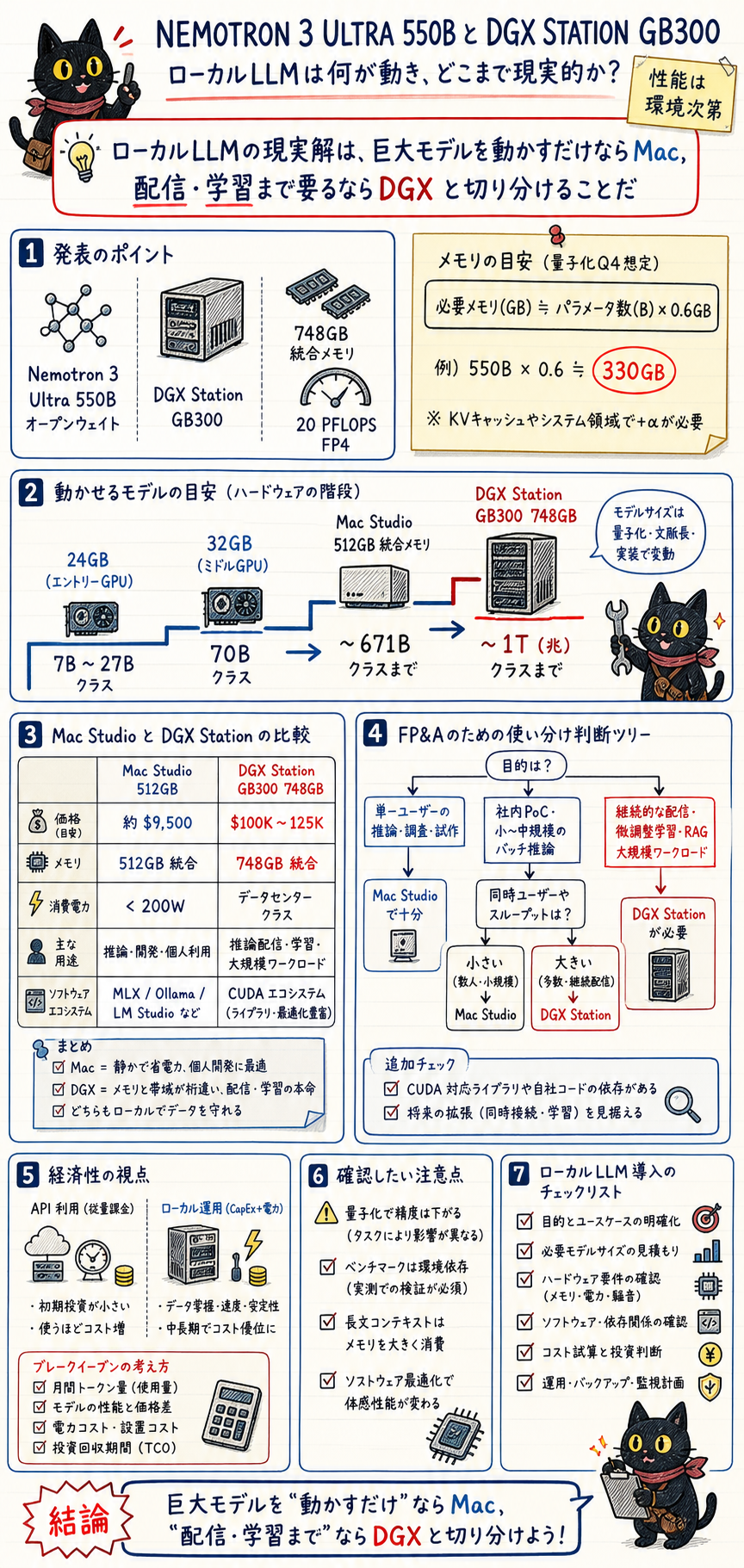
ローカルLLMは「どこまで」「どれだけ簡単に」動くか(2026年の実機事情)
Q4量子化のおおよその所要VRAM ≈ パラメータ数(B) × 0.6 GB。
例: 70B → 約42GB、550B → 約330GB、671B → 約400GB。
Mac の「unified memory」はCPU/GPUでメモリプールを共有するため、512GB機なら約448GBをGPUワークに割り当て可能。
運用の容易さ(ツール):
- Ollama: ターミナル1コマンドでローカルAPIが立つ。モデル取得・量子化選択・GPUオフロードを自動化、OpenAI互換REST APIを標準提供。事実上の標準CLI/サーバ
- LM Studio: GUIでHugging Faceから1クリックDL、:1234でOpenAI互換サーバ。GUI派の開発者向け
- MLX(Apple Silicon専用): Apple Silicon上で最速、新モデルを発売当日サポートすることが多い
「どこまで動くか」のハードウェア階段:
| 階層 | 代表ハード | 実用的に動くモデル規模 | 体感 |
|---|---|---|---|
| ノート/エントリGPU(8-24GB) | RTX 4060-4090、M4 16-32GB | 7B-27B 快適、70Bは厳しい | 入門。Mistral 7B/Phi系/Qwen 27B |
| ハイVRAM単GPU(32GB) | RTX 5090 | 70B Q4 ぎりぎり、MoEは快適 | Llama 4 Scout(MoE)が"modest hardwareで大型"の勝者 |
| 大容量統合メモリ(512GB) | Mac Studio M3 Ultra 512GB | 最大671B(DeepSeek R1) を 16-18 tok/s・<200W | 単一ユーザーで"巨大モデルを机上"の現実解 |
| デスクサイドスパコン(748GB) | NVIDIA DGX Station GB300 | trillion級・複数ユーザー配信・学習も | CUDA本番運用。ただし$100K超 |
ポイント — FP&Aの勘所
Mac Studio vs DGX Station — 10倍の価格差をどう読むか
KK の核心の問い。両者は「巨大モデルをデスクで動かす」点で競合するが、目的が違う。
| 評価軸 | Mac Studio M3 Ultra 512GB | NVIDIA DGX Station GB300 |
|---|---|---|
| 価格 | 約$9,500(約145万円) | 約$100K-125K(MSI版$85K) |
| メモリ | 512GB unified | 748GB coherent(HBM3e含む) |
| AI演算 | (非公表、推論特化) | 20 PFLOPS FP4 |
| 実証済み最大モデル | DeepSeek R1 671B @16-18 tok/s | trillion級 |
| 消費電力 | <200W(省電力が圧倒的) | データセンター級(はるかに大) |
| エコシステム | MLX/Ollama/LM Studio(推論中心) | CUDA+NVIDIA AI Enterprise(学習・本番配信) |
| 得意領域 | 単一ユーザーの推論・実験・PoC | マルチユーザー配信・ファインチューニング・CUDA依存の本番 |
| 苦手 | プレフィル/スループット、CUDA非対応、学習 | 価格、消費電力、過剰スペック |
Mac が巨大モデルを動かせる理由は unified memory(CPU/GPUがメモリプール共有)。
VRAMとシステムメモリが分離した一般PCと違い、512GBをまるごとモデルに使える。
ただし演算スループット(特にプレフィル=長文入力処理)とバッチ処理はCUDA勢に劣り、複数ユーザー同時配信や学習には向かない。
「巨大モデルを単一ユーザーで推論したいだけ」なら Mac Studio 512GB が1/10の価格で足りる。
DGX Station が要るのは ①CUDA前提のライブラリ(vLLMのバッチ配信等)②ファインチューニング/学習 ③部門全体への同時配信、が必要なとき。
多くのバックオフィスPoCは前者で十分で、$100K の投資判断の前に「本当に学習・配信が要るか」を切り分けるのがFP&Aの仕事。
Nemotron 3 Ultra 550B は「Macで動く」— これが最大の含意
Nemotron 3 Ultra 550B を Q4量子化すると所要メモリは約 330GB。
Mac Studio 512GB(GPU割当~448GB)に収まる。
つまり「フロンティア級の open weights 550B モデルを、$100KのDGXでなく$9,500のMac Studioで自社ホストできる」可能性が高い。
これが「self-hosted enterprise AI が現実化」の具体的な意味。
API課金からオンプレ推論への移行閾値が、数百万円規模まで下がった。
もし深堀するなら
- DGX Station for Windows の実体: 従来 DGX は DGX OS(Linux)。「for Windows」版が何を意味するか(WSL2/コンテナ/ネイティブ)を NVIDIA 公式で確認。情シスのWindows資産との親和性が導入障壁を左右
- PinchBench の中身: 「単純QA」でなく「長時間タスクをエージェントが完遂できるか」を測る agentic ベンチ。MMLU等のstaticベンチから agentic ベンチへ社内AI評価指標を移す検討材料。ただし91%はNVIDIA主張で第三者検証が要る
- 量子化と精度のトレードオフ: Mac の 671B/550B 実行は Q4前提。量子化で精度がどれだけ落ちるか、FP&A の数値タスク(計算・抽出)で実用に耐えるかは別途検証が必要
- Mac の弱点=プレフィル/同時実行: 長文コンテキスト(決算書PDF丸ごと等)の処理や、部門複数名の同時利用ではMacのスループットが頭打ちになる。用途が「長文・多人数」ならDGX/クラウド寄り
- 電力・空調・運用: DGX Station はデータセンター級電力=オフィス設置に電源/空調の確認が要る。Mac は<200Wで一般コンセントで動く。TCO(電気代・運用)まで含めた比較が必要
観点:自分のFP&Aへの示唆
- 「自社ホストの損益分岐」を実数で組める — Anthropic/OpenAI API への月次支払いを「capex 1回+電力代」に置き換える試算が現実的に。Mac Studio 512GB($9,500)÷ 想定利用月数 + 電力(<200W)と、API月額を比較する損益分岐表を作れる
- $100K の前に「学習・配信が要るか」を切り分ける — DGX Station の投資稟議が来たら、まず「単一ユーザー推論ならMacで1/10」という対案を出す。過剰スペック投資を止めるのがFP&Aの価値
- 経理部門単独のAI Labという選択肢 — open weights × デスクサイドの組み合わせは、情シスの承認待ちなしに「経理部門のAI Lab」をMac Studio 1台で立てる選択肢を作る。来年度Capex検討の具体案件になり得る
- ソブリン/データ統制の現実解 — 「Anthropic APIに出せないデータ」を扱う場面で、Nemotron 3 Ultra 550B の自社ホストが現実解に。ただし"誰のローカルにどの数字が居るか"のデータ統制が新課題(Snowflake-2026転換-CoWork-CoCo-Observe-Natoma-agentic-control-layer の governance 論点と接続)
- 経済地代がどこに貯まるか — NVIDIAが無料で550Bをばら撒く一方、Anthropic/OpenAI は巨額調達。インフラ(NVIDIA)が地代を取り、モデルはコモディティ化、上層アプリ(SAP/Salesforce・自社内製)に粗利が残る、というバリューチェーン仮説が見えやすくなった
API課金を月$2,000(約30万円)使う部門が、Mac Studio M3 Ultra 512GB($9,500≈145万円)を買って Nemotron 3 Ultra 550B を自社ホストすると、約5か月(145万 ÷ 30万)で初期投資を回収(電力<200Wは月数百円規模で無視できる)。
DGX Station($100K≈1,500万円)なら回収は50か月=4年超。
「単一ユーザー推論」用途なら、Macの損益分岐が圧倒的に早い。
学習・多人数配信が無いなら$100Kは過剰投資。
関連リンク
- 横串(ガバナンス=自社ホストの裏課題): Snowflake-2026転換-CoWork-CoCo-Observe-Natoma-agentic-control-layer
- 横串(AIインフラ投資の評価額・地代論): Anthropic-SeriesH-965B評価
📱 X投稿文案(昇格成果物)
⚠ 投稿前に一次URL再特定要(現状は二次URL〔wccftech〕使用)。NVIDIA 公式 newsroom で Nemotron ライセンス・PinchBench を一次照合のこと。
案A:主要切り口(数値インパクト)
NVIDIAが「自社ホストAI」の閾値を下げた:
・Nemotron 3 Ultra=550B、open weights、商用可
・DGX Station GB300=748GBメモリ、20 PFLOPS、デスクサイドでtrillion級推論
・価格は約$100K-125K
API課金→オンプレ推論への移行が経済的に成立し始めた。
#AI #NVIDIA #ローカルLLM
https://wccftech.com/nvidia-dgx-station-upgraded-gb300-blackwell-ultra-desktop-superchip/
文字数: 約180字
案B:別切り口(Macとの比較=現実解)
「ローカルLLMはどこまで動く?」をMacで答える:
Mac Studio M3 Ultra 512GB(約$9,500)はDeepSeek R1 671Bを16-18 tok/s・200W未満で実行。
550Bモデルなら約330GBで楽勝。
巨大モデルを"単一ユーザーで机上推論"なら、$100KのDGXより1/10のMacが現実解。
#ローカルLLM #AppleSilicon
https://www.techradar.com/pro/apple-mac-studio-m3-ultra-workstation-can-run-deepseek-r1-671b-ai-model-entirely-in-memory-using-less-than-200w-reviewer-finds
文字数: 約190字
案C:FP&A角度(損益分岐)
NVIDIA Nemotron 3 Ultra 550Bの本当の意味、FP&A視点:
330GB(Q4)で動く=$9,500のMac Studio 512GBに載る。
API月$2,000の部門なら、Mac自社ホストで約5か月で回収。DGX Station($100K)は学習・多人数配信が無ければ過剰投資。
「$100Kの前に、本当に学習・配信が要るか」を切り分けるのがFP&Aの仕事。
#FPA #AI #ローカルLLM
https://wccftech.com/nvidia-dgx-station-upgraded-gb300-blackwell-ultra-desktop-superchip/
文字数: 約230字
🖼️ 画像生成 handoff seed(C3契約)
handoff先: 経路A .agents/skills/infographic/SKILL.md(Gemini) / 経路B codex(手動)
実行責務: スキル外(このセクションは seed プロンプトの提供までで完了)
seed プロンプト:
ローカルLLMの「どこまで動くか」とMac vs NVIDIA比較を黒板アート風インフォグラフィックに。
中央に大きく「ローカルLLMはどこまで動く?」のキャッチ。
左に階段グラフ(24GB→7-27B / 32GB→70B / Mac Studio 512GB→671B / DGX Station 748GB→trillion級)。
右に Mac Studio vs DGX Station の対決表($9,500 vs $100K、512GB vs 748GB、200W vs データセンター級、MLX/Ollama vs CUDA)。
下部に「Nemotron 3 Ultra 550B=330GBで$9,500のMacに載る」のハイライトと損益分岐「API月$2,000なら5か月で回収」。
MacとGPUタワーのアイコン。
スタイルは dlab-ai-channel 風、白チョーク、日本語フォント、16:9(X投稿用)。